5 Engineering Lessons from Early Stage Startups

Over the past three years, I’ve left behind a 10-year stint leading an engineering team building enterprise, commercial SaaS- for customers like Novo Nordisk and Boehringer-Ingelheim - and dove head-first into the VC-backed startup world as well as working on my own startups like Turas.app.
In that time, I’ve worked with a range of companies in different stages of maturity from seed-stage to Series B/C and re-oriented my engineering mindset significantly around architecture, technical design, engineering practices, and teams.
I present an assortment of thoughts and reflections based on 2+ years with stints across 4 VC-backed startups, including a YC alum.
Put a Premium on Reducing Complexity
In general, pick simple, stupid solutions that are easy to operationalize rather than complex, expensive, operationally intensive solutions better suited for later stages.
Three big lessons:
- Do not prematurely build microservices; prefer a monolith for as long as it makes sense.
- Do not prematurely adopt GraphQL; prefer REST until you have a very solid use case for GraphQL — generally when you need an API of APIs.
- Do not prematurely deploy Kubernetes; prefer a serverless compute option for as long as your use case allows.
All three introduce operational complexity, development friction, and complicate your hiring/onboarding process by demanding a deeper skillset from your first hires.
There’s a time and a place to consider moving to each of these paradigms.
Microservices: once you start to have separate teams that need to deploy on separate schedules or have teams that own entirely different technology stacks as part of the same solution. Or some part of the system is more economical to operate and scale separately from other parts of the system. Microservices make sense as a reflection of organizational, process, and infrastructure boundaries and not simply as application interfaces.
GraphQL: once you start to adopt microservices, then GraphQL makes much more sense as an API of APIs; a gateway to the different microservices. If you only have one API at the onset, then GraphQL increases the level of complexity with very little benefit. Since you’re working full-stack with a single API in the early days anyways, it’s easy enough to just shape your REST responses exactly how you want in the front-end and reap the benefits of the simplicity of REST.
Kubernetes: early on, only if your domain requires control of the underlying virtual hardware (and even then, perhaps it may be better to use a VM to start). There will be an inflection point when operating a K8s cluster will become either necessary due to constraints on serverless alternatives or the pricing of the K8s option (including the expertise) becomes cheaper than the serverless option.
My advice mirrors Matt Rickard’s: favor serverless container options like Google Cloud Run, AWS App Runner, or Azure Container Apps early on as it provides the best balance of flexibility, portability, scalability, cost, and operational simplicity. Cloud Run is particularly low in ceremony and wasted effort.
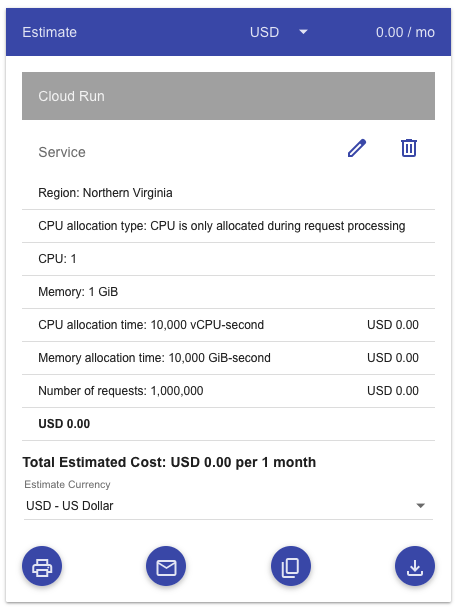 $0 per month for a Cloud Run app that runs on 1 CPU, 1 GiB memory, accepting 20 concurrent requests at 200ms each with 1 million invocations.
$0 per month for a Cloud Run app that runs on 1 CPU, 1 GiB memory, accepting 20 concurrent requests at 200ms each with 1 million invocations.
A great read if you’re interested in diving deeper and getting more opinions: https://news.ycombinator.com/item?id=31795160
Pick Platforms with Low Cognitive Load
This is a corollary to the first, but pick platforms and approaches that have a low cognitive load. Early on, it can be difficult to attract senior level and higher grade engineers, especially when bootstrapping. Hiring dedicated devops is out of the question. Your first hires are likely to be more junior and full-stack rather than specialized.
To align with that, favor platforms that have a lower cognitive load to build, deploy, and operationalize so that it is easier to onboard even junior- and mid-level engineers that do not have strong devops or infrastructure backgrounds.
I’m particularly fond of Google Cloud Firebase as the excellent CLI and local emulator support make it easy to build quickly with minimal experience operationalizing infrastructure. A single deploy command firebase deploy is enough to deploy a static app or an SSR app, backend functions, and data access and file storage authentication rules. Even the CDN is easier to interact with compared to AWS CloudFront (less feature rich, but easier!).
Google Cloud’s Pub/Sub includes an HTTP push built into it (whereas it is necessary to build, deploy, and operate a Lambda to do the same in AWS with SNS/SQS). Google Cloud Task Queues also allow queue processing using simple HTTP endpoints - a great fit with a monolithic backend.
If you’re tied to AWS, the AWS Copilot CLI is the best way to deploy and operate infrastructure. For example, a basic cron scheduled job is significantly easier to package and deploy via Copilot than manually building the equivalent CDK or CloudFormation or even UI configuration to do the same.
As the business grows and the company starts generating cash flow, later hires can bring the specialized knowledge necessary to design and build the more complex solutions required to support continued growth and scaling.
Don’t Optimize Prematurely; Do Plan a Route to Grow
Fred Brooks wrote of a phenomenon called the “second system effect” in his collected essays The Mythical Man Month:
This second is the most dangerous system a man ever designs.
The gist of it is that such systems tend to become overly complex as a result of lessons learned and misapplied from the previous system. A startup needs to be optimized differently than a mature company and a mature product.
But teams should still make choices that provide a clear route for growth; don’t build into a corner with no option but to scrap it. Understand the compromises being made today and how to mitigate them as the need arises. For example, using serverless containers like Google Cloud Run means that those containers can be moved to Kubernetes later on if it makes sense to do so. Writing serverless functions means you’re stuck with significantly less flexibility within the constraints of the platform even as your needs evolve.
Writing a “modular monolith” still promotes development and operational speed, but allows eventually replacing parts of it piecemeal with microservices as the situation arises.
Some design decisions early on can have an outsized impact on scaling, costs, and momentum. It’s not necessary to have a solution designed for 10,000 TPS when starting with the first few MVP customers, but if possible, make technical decisions that provide flexibility and provide a route to scaling from 10 TPS to 10,000 TPS as needed.
In other words, don’t over-engineer the solution for scalability, but instead spend that effort in engineering for a malleable codebase. As Martin Fowler has written on the topic of “You Aren’t Gonna Need It”,
Yagni only applies to capabilities built into the software to support a presumptive feature, it does not apply to effort to make the software easier to modify.
The gap between “getting it done” and “doing it right” can be quite large, but often, the gap from “getting it done” and “doing it better” is small enough that it is likely worth the effort if it reduces complexity, increases malleability, and reduces the burden of dragging around working but hard to maintain code.
One thing I’ve realized is that this can be a matter of perspective gained from experience. For a younger engineer or any non-engineer, “doing it better” may be mistaken for premature optimization because that gap from “getting it done” is an unknown quantity.
Don’t Skimp on Documentation
Documentation is how teams can accelerate onboarding and knowledge transfer.
For small teams, having sufficient, well-organized documentation in place can ensure that responsibilities aren’t siloed and anyone can pick up some piece of responsibility as needed (like fixing a CI/CD pipeline, debugging some deployment issue, adding a new module, etc.). In that respect, good documentation is a force multiplier since it empowers anyone to pick up some responsibility with minimal hand-holding.
Whether it’s Notion or a README, don’t skimp on taking notes on key responsibilities like operations and deployment. It is a lot easier to capture notes in-the-moment then to reconstruct reasoning and technical decision making rationale later on.
Because the early days involve a lot of tradeoffs in the name of speed, documenting those tradeoffs and future mitigation plans can pay dividends down the line. Even if parts of the system end up being tossed, having a record of the rationale at the earlier junctures of decision making can help avoid mistakes when making later decisions.
In general, promoting a strong written culture is beneficial for early stage startups because it allows teams to work remotely in a more decoupled manner while setting the foundation for accelerating future onboarding. Equally important is that if only one person on the team knows the magic incantation required to perform some function, that person becomes the bottleneck and a risk.
Hire for Curiosity, Drive and Potential - not for Experience and Resume; Avoid Inflexible Mindsets
A startup is a different kind of beast than an enterprise. The early days require adaptability and flexibility. As Carol Dweck would put it: a “growth mindset” over a “fixed mindset”.
A fixed “capacity” is easy to measure by simply examining the exterior dimensions - experience, resume, and tests.
Capacity is valuable when the problem space is well-defined. When it is well understood what needs to be built and how it is to be built, it is then possible to cross-check the dimensions to see if there is a fit.
Growth “potential” is much harder to measure but in return provides more value because it is pliable and flexible; adaptive to the needs of the startup at every twist and turn where every member of the team needs to be able to pick up some responsibility.
A good proxy for measuring potential is curiosity. Find those that are curious and enjoy learning. Perhaps above all else, a startup is a continuous learning experience.
