.NET Task Parallel Library vs System.Threading.Channels
A friend reached out recently regarding the usage of Task Parallel Library (TPL) and ConcurrentBag in some .NET code. I inquired what the code was doing and it turns out that for each entry in some workload, it was performing some database operations and API calls.
I immediately wondered if using .NET’s System.Threading.Channels (STC) wouldn’t be a better choice: likely higher throughput and easier to program.
Let’s take a look!
First Thoughts
Intuitively, the nuance with TPL is that constraining the degree of parallelism means that the maximum number of tasks waiting at any given time is governed by the configured degree of parallelism (more on this in the caveats at the end); the rest of the tasks will be queued. This means that throughput is strongly dependent on properly selecting a MaxDegreeOfParallelism.
For any workload where there’s a network dependency within the parallel execution, this means that there would be significant constraints on how quickly the workload would complete since much of the time is likely spent waiting for network I/O.
Furthermore, when using TPL, it is then necessary to use synchronized access to shared state, which would again increase wait times, especially as the degree of parallelism increases (we won’t explore this angle in this article).
So let’s build a test case.
Test Design
The test design is simple: we’ll create a workload with 100 items in it, each with a random delay between 10 and 50ms to simulate some I/O:
var workload = Enumerable
.Range(0, 100)
.Select(i => (Index: i, Delay: Random.Shared.Next(10, 50)))
.ToImmutableArray();A helper method will wrap the execution of each of our test cases to provide some basic instrumentation:
async Task InstrumentedRun(string name, Func<Task> test) {
var threadsAtStart = Process.GetCurrentProcess().Threads.Count;
var timer = new Stopwatch();
timer.Start();
await test(); // ⭐️ Actual test here.
timer.Stop();
Console.WriteLine($"[{name}] = {timer.ElapsedMilliseconds}ms");
Console.WriteLine($" ⮑ {threadsAtStart} threads at start");
Console.WriteLine($" ⮑ {Process.GetCurrentProcess().Threads.Count} threads at end");
}Now we can run a few cases and measure the results.
Using a Channel
First up is using a channel:
// Using System.Threading.Channels
await InstrumentedRun("Channel", async () => {
var channel = Channel.CreateUnbounded<int>();
async Task Run(ChannelWriter<int> writer, int id, int delay) {
await Task.Delay(delay); // ⭐️ Simulate work
await writer.WriteAsync(id);
}
async Task Receive(ChannelReader<int> reader) {
while (await reader.WaitToReadAsync()) {
if (reader.TryRead(out var id)) {
// No work here, but you can log to see the output stream
}
}
}
var receiveTask = Receive(channel.Reader); // Set up the reader
var processingTasks = workload // Execute the writers
.AsParallel()
.Select(e => Run(channel.Writer, e.Index, e.Delay));
await Task // Wait for everything to complete
.WhenAll(processingTasks)
.ContinueWith(_ => channel.Writer.Complete());
await receiveTask;
});We start by creating a simple channel and the two methods that will hold on to each of the two ends of the channel (writer and reader). The Run method is invoked and returns a set of 100 Tasks which we’ll wait for and upon completion, notify the read end with a call to Complete().
Using Parallel.For @ 4
Next we’ll set up Parallel.For with a MaxDegreeOfParallelism of 4:
// Using Parallel.For with concurrency of 4
await InstrumentedRun("Parallel.For @ 4", () => {
Parallel.For(0, 100,
new ParallelOptions { MaxDegreeOfParallelism = 4 },
index => {
Thread.Sleep(workload[index].Delay); // ⭐️ Simulate work
}
);
return Task.CompletedTask;
});Note that Parallel.For does not support async/await so we simply use Thread.Sleep here to suspend the current thread for the configured delay.
Using Parallel.ForEachAsync @ 4
Next, we’ll use an async version with Parallel.ForEachAsync:
// Using Parallel.ForEachAsync with concurrency of 4
await InstrumentedRun("Parallel.ForEachAsync @ 4", async () =>
await Parallel.ForEachAsync(workload,
new ParallelOptions { MaxDegreeOfParallelism = 4 },
async (item, cancel) => {
await Task.Delay(item.Delay, cancel); // ⭐️ Simulate work
}
)
);Using Parallel.ForEachAsync @ 40
Then we’ll try with the parallelism set to 40:
// Using Parallel.ForEachAsync with concurrency of 40
await InstrumentedRun("Parallel.ForEachAsync @ 40", async () =>
await Parallel.ForEachAsync(workload,
new ParallelOptions { MaxDegreeOfParallelism = 40 },
async (item, cancel) => {
await Task.Delay(item.Delay, cancel); // ⭐️ Simulate work
}
)
);Using Parallel.ForEachAsync with Defaults
And finally, we’ll try with the defaults:
// Using Parallel.ForEachAsync with concurrency unset
await InstrumentedRun("Parallel.ForEachAsync (Default)", async () =>
await Parallel.ForEachAsync(workload, async (item, cancel) => {
await Task.Delay(item.Delay, cancel); // ⭐️ Simulate work
})
);Let’s take a look at the results and analysis:
Results
Each run will be a bit different since the initialization of the workload is random. Here’s the output from one run:
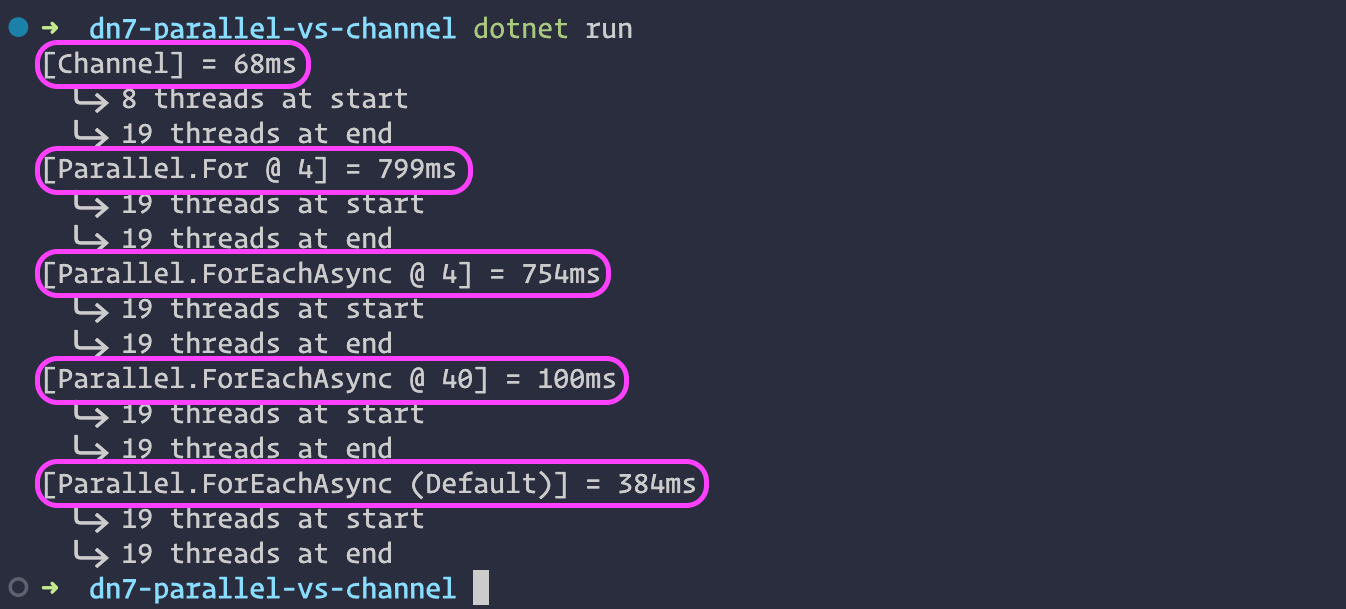
Is this what you expected?
If not, then you may want to consider whether TPL or STC is the better concurrency paradigm to use if you’re after raw performance (unless you really know how to tune your MaxDegreeOfParallelism).
The STC implementation is almost 12x faster than the TPL implementation at 4 degrees of parallelism. Of course, intuitively, this makes sense: since only 4 tasks can be executing at once with MaxDegreeOfParallelism set to 4, any I/O in the task will cause queuing of the remaining 96 tasks. On the other hand, the STC implementation immediately executes the full workload until each task hits I/O.
Even at 40 degrees of parallelism, the TPL implementation is necessarily slower than the STC implementation. Since we have a total of 100 tasks to process, it means that after the first 40 enter a wait state, the remaining 60 are going to be queued. The STC implementation effectively executes all 100 tasks until they reach a waiting state.
What may be a bit surprising is the thread count: it never rises above 19. As the name “Task Parallel Library” suggests, it is in fact processing tasks using the process thread pool and even if we set the MaxDegreeOfParallelism to 40, the process does not spawn the corresponding number of threads. In other words, it’s a concurrent-parallel hybrid.
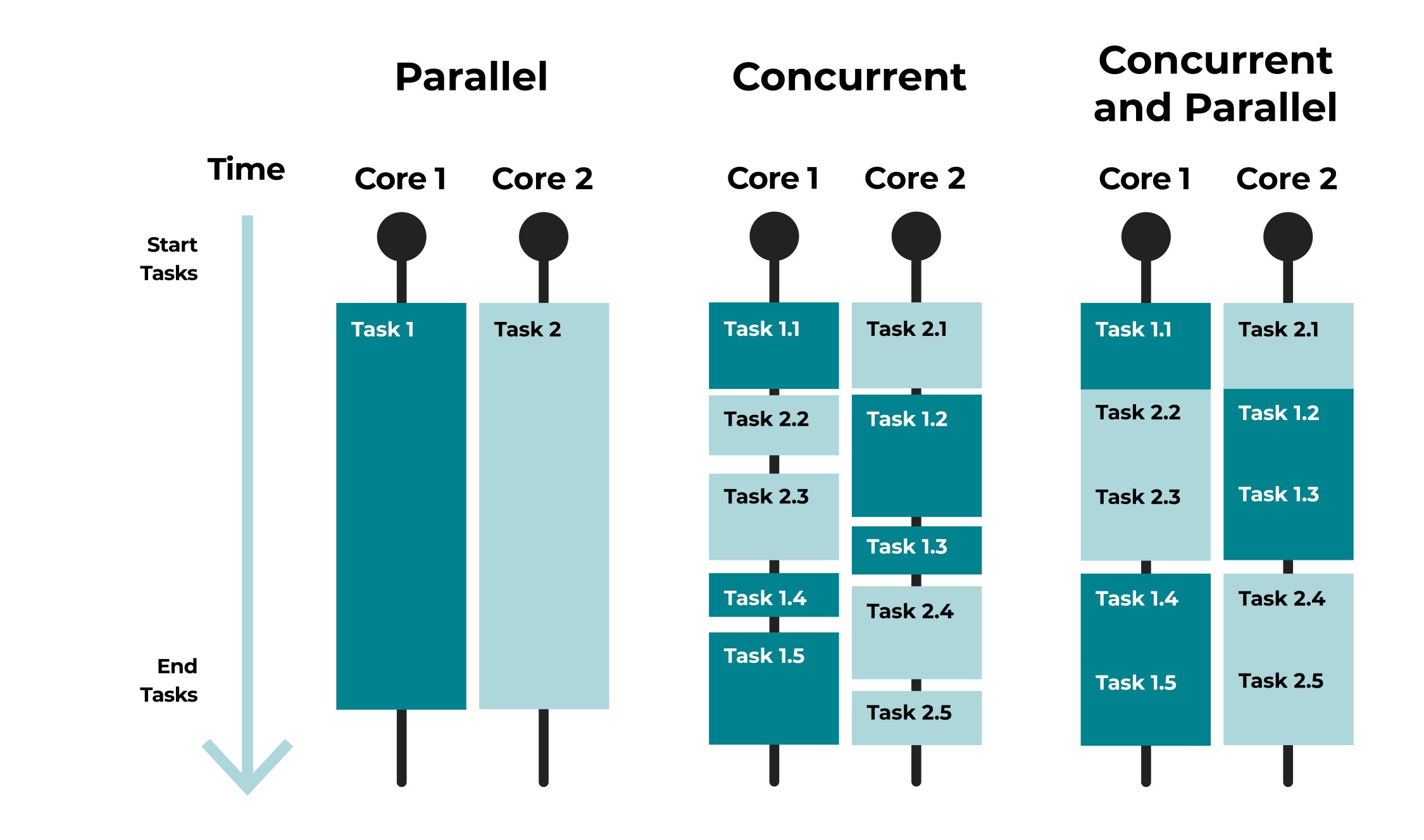 Understanding the difference between concurrent, parallel, and hybrid. Diagram via OpenClassrooms.com
Understanding the difference between concurrent, parallel, and hybrid. Diagram via OpenClassrooms.com
(It’s worth running this code yourself and switching the order of the Channel case to the last one and see how that affects the thread count).
Caveats and Conclusion
One important caveat here is that the STC approach effectively runs everything. This means that it can be unsuitable for cases where the upstream system (an API or database) cannot handle the volume from a sudden burst of requests or there is a request quota or contention for some resource (e.g. write lock in the DB). In such cases, TPL may be a suitable way to implement a sort of “throttled” concurrent request processing.
Another factor to consider is synchronized access. The beauty of the STC approach is that it effectively serializes the data flow and it is possible to handle the output in the Receive loop as if it were single-threaded (because it is). I think that this simplifies the programming model (perhaps also easier to debug) and writing to synchronized state in the TPL case would probably introduce additional costs, especially as parallelism increases.
A throttled STC implementation is also possible by introducing two serial Channels so if there is some portion of the workload that should be throttled, it is possible to execute the non-throttled part of the workload immediately as fast as possible and then control the flow of the throttled part of the workload.
The conclusion is that if your workload is using Task Parallel Library, it’s important to understand the correct tuning of the MaxDegreeOfParallelism to achieve the target throttling behavior. Not explicitly setting the parallelism seems the worst of both worlds since you’re not explicitly throttling the workload but at the same time, constraining the throughput. In cases where there’s no throttling involved nor desired, using System.Threading.Channels would seemingly be a better choice providing both better performance and perhaps an easier, sans-synchronization programming model.
The full sample code is available here: https://gist.github.com/CharlieDigital/51e7457a01c5ade7c172771bdaf82e1c
If you’d like to learn more about .NET Channels, check out my other article on Concurrent Processing in .NET 6 with System.Threading.Channels (Bonus: Interval Trees).
If you’d like to explore other options for building concurrent/parallel systems in .NET, check out:
- ZeroMQ: socket abstraction for building distributed, multi-node clusters
- DotMP: a .NET implementation of OpenMP
If you’re looking for more practical examples of System.Threading.Channels, check out these posts:
- C# Discriminated Unions and .NET Channels (2024-07-06)
- Need for Speed: LLMs Beyond OpenAI with C#, .NET 8 SSE + Channels, Llama3, and Fireworks.ai (2024-05-05)
- Concurrent Processing in .NET 6 with System.Threading.Channels (Bonus: Interval Trees) (2022-11-06)
Special Note
AliveDevil pointed out in the gist that the performance of the Parallel.ForEachAsync @ 40 actually beats the STC implementation when using the following build:
dotnet publish -c Release --self-contained \
-p:PublishNativeAot=true \
-p:PublishSingleFile=true \
-p:PublishTrimmed=trueMy initial thought is that the native AOT compilation may be introducing some optimization into the task/thread scheduling to improve the performance of the TPL case.
However, it turns out that the PublishTrimmed flag penalizes the STC implementation (possibly causing the allocation cost of the Channel to increase or introducing undesirable lock behavior on the underlying ConcurrentQueue?).
