Merging Objects in Google Cloud Storage with Compose and C#
Summary
- When working with large dataset ETL, it can be useful to “checkpoint” your output to reduce costs if something fails.
- Google Cloud Storage offers a nifty feature called object composition for merging multiple objects into one
- This feature has some limits, but ultimately provides a useful way to perform ETL steps with a “checkpoint” to reduce the cost of recovery.
Google Cloud Storage Object Composition
Google Cloud Storage has a really nifty feature that allows you to “compose” multiple storage objects into one.
This can be really useful if you’re performing ETL-like tasks across a large dataset and you want to add resiliency to your process by allowing you to “checkpoint” your work by simply dumping out state into a storage object. For example, imagine that you are moving data from an API and processing a large resultant CSV file (think tens of thousands of records).
That API call may be costly and may be subject to rate limiting. So what happens if your process fails? To solve for this, we can simply periodically dump out a fragment of our extract. For example, imagine that we are extracting 30 days of data from some API. We can simply dump out 1 day at a time and then at the end, merge all 30 days into one large object for the next step of processing.
Let’s explore how we can achieve this with C# and .NET
Getting Set Up
First, let’s set up our project:
mkdir gcp-storage-compose
cd gcp-storage-compose
dotnet new console
dotnet add package Google.Cloud.Storage.V1Next, you’ll want to grab your account credential key (.json file) for authenticating. As far as I’m aware, there is no storage emulator and the Firebase storage emulator does not support this feature (your API call will fail).
Creating the Fragments
Let’s start by creating the fragments:
using System.Text;
using Google.Apis.Auth.OAuth2;
using Google.Apis.Storage.v1.Data;
using Google.Cloud.Storage.V1;
var credential = GoogleCredential.FromFile("credentials.json");
var storage = StorageClient.Create(credential);
var run = Random.Shared.Next(100, 10000000);
var bucket = "__YOUR_BUCKET_HERE__";
var count = 10;
var fragments = Enumerable
.Range(0, count)
.Select(i => $"{run}/fragment-{i}.csv")
.ToArray();
var tasks = fragments.Select(async path => {
using var stream = new MemoryStream();
var content = Encoding.UTF8.GetBytes(
$"LINE FOR: {path}{Environment.NewLine}"
);
await stream.WriteAsync(content);
await storage.UploadObjectAsync(bucket, path, "text/csv", stream);
});
Task.WaitAll([.. tasks]);The run identifies a unique folder into which we’ll place 10 objects which represent individual fragments of a .csv file.
Then we can merge it into 1:
// Merge into 1
await storage.Service.Objects.Compose(
new() {
SourceObjects = fragments
.Select(path => new ComposeRequest.SourceObjectsData() {
Name = path
})
.ToList(),
Destination = new Google.Apis.Storage.v1.Data.Object {
ContentType = "text/csv"
}
},
bucket,
$"{run}/__merged.csv"
)
.ExecuteAsync();If we execute this, we’ll see that we generate 10 files and dump out a merged file! Sweet!
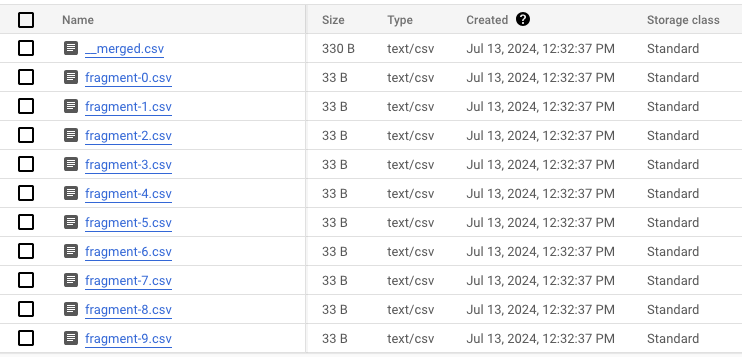
How far can we take this?
Probing the Limits
Let’s up this to 1500 objects:
var count = 1500;And our first stumbling block:
Unhandled exception. The service storage has thrown an exception.
HttpStatusCode is BadRequest.
Google.Apis.Requests.RequestError
The number of source components provided (1500) exceeds the maximum (32) [400]
Errors [
Message[The number of source components provided (1500) exceeds the maximum (32)] Location[ - ] Reason[invalid] Domain[global]
]So the maximum number of individual items we can compose is limited to 32.
We’ll need to change how we do the composition into chunks.
Refactoring for Chunking
Let’s first extract a function that encapsulates the composition:
var compose = (string[] paths) => {
storage.Service.Objects.Compose(
new() {
// 👇 Always stuff the first fragment into the paths
SourceObjects = ((string[])[fragments[0], .. paths])
.Select(path => new ComposeRequest.SourceObjectsData() {
Name = path
})
.ToList(),
Destination = new Google.Apis.Storage.v1.Data.Object {
ContentType = "text/csv"
}
},
bucket,
fragments[0] // 👈 Overwrite the first object
)
.Execute();
};Our strategy is simple: whatever the first fragment is, we’ll just compose everything into it iteratively.
Now we need to aggregate our fragments into one:
fragments
.Skip(1) // Skip the first one since we'll always insert this.
.Chunk(31) // Take in chunks of 31 since we'll always insert one.
.ToList() // Get all of our chunks
.ForEach(compose); // Compose each chunk in turnAnd here is our output file:
LINE FOR: 1729868/fragment-0.csv
LINE FOR: 1729868/fragment-1.csv
LINE FOR: 1729868/fragment-2.csv
LINE FOR: 1729868/fragment-3.csv
LINE FOR: 1729868/fragment-4.csv
LINE FOR: 1729868/fragment-5.csv
....
LINE FOR: 1729868/fragment-37.csv
LINE FOR: 1729868/fragment-38.csv
LINE FOR: 1729868/fragment-39.csvNice!
With this mechanism in place, then we can easily checkpoint and dump out a partial CSV as we process a large dataset.
If we need to restart, simply check if the dataset already exists in Cloud Storage and add the path if it does. Otherwise, process the chunk and dump out a CSV.
If we fail at row 40,000 of 100,000, we don’t have to start at 0 and instead, we can just pick up at 40,001 instead.
Then on a successful run, merge everything into the first file.
Deleting the Excess Objects
Once we’ve merged the objects, we can actually simply delete them.
Let’s add that in:
var compose = (string[] paths) => {
storage.Service.Objects.Compose(
new() {
SourceObjects = ((string[])[fragments[0], .. paths])
.Select(path => new ComposeRequest.SourceObjectsData() {
Name = path
})
.ToList(),
Destination = new Google.Apis.Storage.v1.Data.Object {
ContentType = "text/csv"
}
},
bucket,
fragments[0]
)
.Execute();
// 👇 We can delete concurrently.
var deletionTasks = paths.Select(
path => storage.DeleteObjectAsync(bucket, path)
);
Task.WaitAll([.. deletionTasks]);
};Now our contents after 1 run:

Only one file remains; keeping everything tidy.
Limited Chunks
What if we actually don’t want 1 massive file? What if we want to compose say every n files in to 1? An example might be a case where each file has 1,000 records and we want resultant files to max out at 10,000 records.
Let’s update our logic here so that we dump out a file for each subset:
var compose = (string[] paths) => {
storage.Service.Objects.Compose(
new() {
SourceObjects = paths // 👈 No longer inserting here
.Select(path => new ComposeRequest.SourceObjectsData() {
Name = path
})
.ToList(),
Destination = new Google.Apis.Storage.v1.Data.Object {
ContentType = "text/csv"
}
},
bucket,
paths[0] // 👈 Compose into the first file
)
.Execute();
var deletionTasks = paths
.Skip(1) // 👈 Skip the first file for deletion
.Select(
path => storage.DeleteObjectAsync(bucket, path)
);
Task.WaitAll([.. deletionTasks]);
return paths[0]; // 👈 Return the path so we can print it
};
var chunkSize = 10;
var paths = fragments
.Chunk(chunkSize) // 👈 No skip here
.ToList()
.Select(compose);
foreach (var path in paths) {
Console.WriteLine(path);
}Here is our output:
➜ gcp-storage-compose dotnet run
5056692/fragment-0.csv
5056692/fragment-10.csv
5056692/fragment-20.csv
5056692/fragment-30.csv
Completed run: 5056692And in storage:
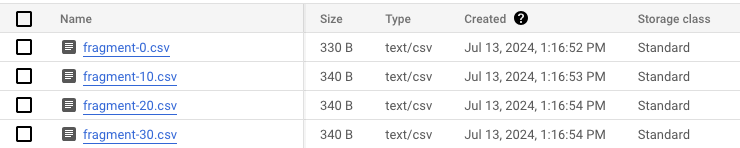
The contents for the first chunk:
LINE FOR: 5056692/fragment-0.csv
LINE FOR: 5056692/fragment-1.csv
LINE FOR: 5056692/fragment-2.csv
LINE FOR: 5056692/fragment-3.csv
LINE FOR: 5056692/fragment-4.csv
LINE FOR: 5056692/fragment-5.csv
LINE FOR: 5056692/fragment-6.csv
LINE FOR: 5056692/fragment-7.csv
LINE FOR: 5056692/fragment-8.csv
LINE FOR: 5056692/fragment-9.csvAnd the second:
LINE FOR: 5056692/fragment-10.csv
LINE FOR: 5056692/fragment-11.csv
LINE FOR: 5056692/fragment-12.csv
LINE FOR: 5056692/fragment-13.csv
LINE FOR: 5056692/fragment-14.csv
LINE FOR: 5056692/fragment-15.csv
LINE FOR: 5056692/fragment-16.csv
LINE FOR: 5056692/fragment-17.csv
LINE FOR: 5056692/fragment-18.csv
LINE FOR: 5056692/fragment-19.csvNice; we can imagine that each of these files had 1,000 rows and now file 1 and file 2 have 10,000 rows each.
Closing Thoughts
If you’re in Google Cloud, this is a neat platform feature that allows you to do interesting things with your ETL type workloads without involving a database for what is ostensibly temporary data.
By check pointing each set of data, it’s possible to avoid potentially costly retries.
Full Code Listing
using System.Text;
using Google.Apis.Auth.OAuth2;
using Google.Apis.Storage.v1.Data;
using Google.Cloud.Storage.V1;
var credential = GoogleCredential.FromFile("credentials.json");
var storage = StorageClient.Create(credential);
var run = Random.Shared.Next(100, 10000000);
var bucket = "__YOUR_BUCKET_HERE__"; // 👈 Replace this
var count = 40;
var fragments = Enumerable
.Range(0, count)
.Select(i => $"{run}/fragment-{i}.csv")
.ToArray();
var tasks = fragments.Select(async path => {
using var stream = new MemoryStream();
var content = Encoding.UTF8.GetBytes($"LINE FOR: {path}{Environment.NewLine}");
await stream.WriteAsync(content);
await storage.UploadObjectAsync(bucket, path, "text/csv", stream);
});
Task.WaitAll([.. tasks]);
var compose = (string[] paths) => {
storage
.Service.Objects.Compose(
new() {
SourceObjects = paths
.Select(path => new ComposeRequest.SourceObjectsData() {
Name = path
})
.ToList(),
Destination = new Google.Apis.Storage.v1.Data.Object {
ContentType = "text/csv"
}
},
bucket,
paths[0]
)
.Execute();
var deletionTasks = paths
.Skip(1)
.Select(
path => storage.DeleteObjectAsync(bucket, path)
);
Task.WaitAll([.. deletionTasks]);
return paths[0];
};
var chunkSize = 10;
var paths = fragments
.Chunk(chunkSize)
.ToList()
.Select(compose);
foreach (var path in paths) {
Console.WriteLine(path);
}
Console.WriteLine($"Completed run: {run}");