On Bakers, Ovens, and AI Startup Moats
Summary
- Many folks who have not worked with LLMs to produce some complex output tend to see most AI startups as simple wrappers around third party models and APIs.
- However, this is the wrong way to think about LLMs and AI. A more accurate analogy is to think of LLMs and AI as an (admittedly magical) oven — an appliance that transforms the input mixture of ingredients into some intermediate product.
- In other words, when evaluating any AI startup, focusing on the oven is the wrong approach. Focus instead on how well the team understands the input ingredients (the data) and how adept they are at preparing that data long before it goes into the “oven” (the LLM).
- Teams that do not invest in deeply understanding, preparing, and structuring the input data sources to the LLM are simply baking supermarket box cake mix; yes of course these are simple wrappers because the effort on the input was low and cheap.
“It’s Just Another Wrapper”
 A misguided response in a Hacker News thread launching the startup Codebuff
A misguided response in a Hacker News thread launching the startup Codebuff
In a recent Hacker News thread launching an AI code generation CLI tool Codebuff, I saw this comment at the bottom:
I don’t really find it exciting at all, I’m sorry. It’s just another wrapper for a 3rd party model. — Hacker News Poster
This is a sentiment that is quite common to come across in the current tech landscape of AI and LLMs where venture capital has started a gold rush in AI-for-{X} with countless startups in the wake of this boom trying to capitalize. Most early “AI startups” really were just thin wrappers for OpenAI, but — believe it or not — some AI startups really can create a moat and that moat is probably not what you think.
Before continuing, it is important to differentiate startups that work on AI (and AI adjacent services) — like OpenAI, Anthropic, Mistral, HuggingFace, et al — and startups that work with AI that use LLMs and gen AI to transform and create content (be that text/code, data, images, or video). Here, let us consider only startups that work with AI.
Having an Oven Does Not a Baker Make
Folks who have not worked heavily with gen AI — day-in, day-out — severely underestimate how difficult it is to get consistently good output from any LLM at the moment. The team at Ownit AI (where I work) first started working with OpenAI around May of 2023 and we’ve spent 18 months learning how to utilize LLMs in an e-commerce context.
What is clear through the many different iterations of services we’ve built around LLMs is just how lacking they are. Let me iterate the ways:
- Without retrieval augmented generation (RAG), the LLM will hallucinate
- A related problem is that, until web search was integrated, the LLM had no way of knowing about knowledge that came after its training data
- Giving it access to web search creates another problem: search has become “enshittified” with ads and spam results so even giving it access to search can be risky
- Of course, it also won’t have knowledge about information that never showed up in its training dataset or search (e.g. private enterprise data)
- Basic RAG has its limits so teams need to continuously find clever ways to improve the RAG like using graph-based RAG
- The LLM’s understanding of instructions for complex tasks is quite “robotic” in that it prefers following very specific instructions and any ambiguity risks undesired/useless output
- Even when given precise instructions on the output format, LLMs often tend to generate incorrect output formats. This was especially bad with JSON early on, but still present today and crops up when generating output in batches of thousands (you will see failures).
- Even with extremely large context windows, LLMs tend to suffer in their comprehension of the context as the window gets larger so there is a need to create as reasonably focused a context as possible not only for speed and cost, but also for accuracy.
In almost all cases, the solution to getting the desired output from the LLM is to fix the input by making the prompt and context data more precise, more targeted, or transformed in a way that makes it more likely to get the desired output from the LLM.
In a sense, this is not unlike baking: the AI is an appliance — the most fantastical and amazing appliance man has made, but yet still an appliance — and the artistry and science all happens before the ingredients go into the oven and we hit “bake”.
Indeed, there are many “AI startups” that quickly fizzled because having an oven does not a baker make and many startups were just content putting supermarket box mix cake batter into the oven and calling it a day.
How AI Startups Build Their Moat
In my 20’s, Alton Brown’s Good Eats series was the first time I had the thought that cooking is equal parts art and science. The preparation and combination of ingredients followed by the application of energy (usually in the form of heat or mixing) fundamentally changes the chemistry and physical properties of the ingredients themselves (I actually think it was specifically his episode on mayonnaise and how the different ingredients play their roles in creating an emulsion).
Watching the recent Netflix cooking competition Culinary Class Wars, I was often reminded of this as I watched the competitors meticulously transform a set of ingredients into incredibly creative dishes. Every detail from how “Triple Star” (a nickname of one of the competitors) finely sliced wonton wrappers to achieve the correct texture when fried to “Napoli Matfia” creating a Tiramisu that wowed the judges using only ingredients available in a convenience store (even extracting the cream filling from a baked pastry).
It is really striking just how deeply the top contestants bring not only their culinary skills, but also their deep understanding of the ingredients and how to use each for the desired effect like changing texture, adding acidity, complementing another flavor, masking some pungent note, and so on. In one challenge, the judge notes that “Triple Star” even meticulously chopped vegetables to be the same size as the caviar for more consistent visual presentation and better mouth feel.
Startups that want to succeed working with AI similarly must understand that the moat is actually in the data:
- How well does the team understand what data is needed and what datasets are available to achieve the desired output.
- How creative the team is in transforming and using that data given the limitations of LLMs.
- How the team thinks about combining different pieces of data to feed context into the LLM.
- How the team puts the finishing touches on the output and presents the results to the consumer (often requiring parsing and transforming once again).
It is not unlike the culinary arts: the best chefs and bakers deeply understand the input ingredients be it their flavor and texture profiles, how they should be shaped for different applications, how they have to be prepared, how one ingredient will complement another, how to combine it all, and how to present the finished product tastefully and creatively. Hitting “bake” on the oven is simply one step that applies heat to combine and transform the ingredients; all of the artistry and science is actually in the preparation steps before and the presentation steps afterwards.
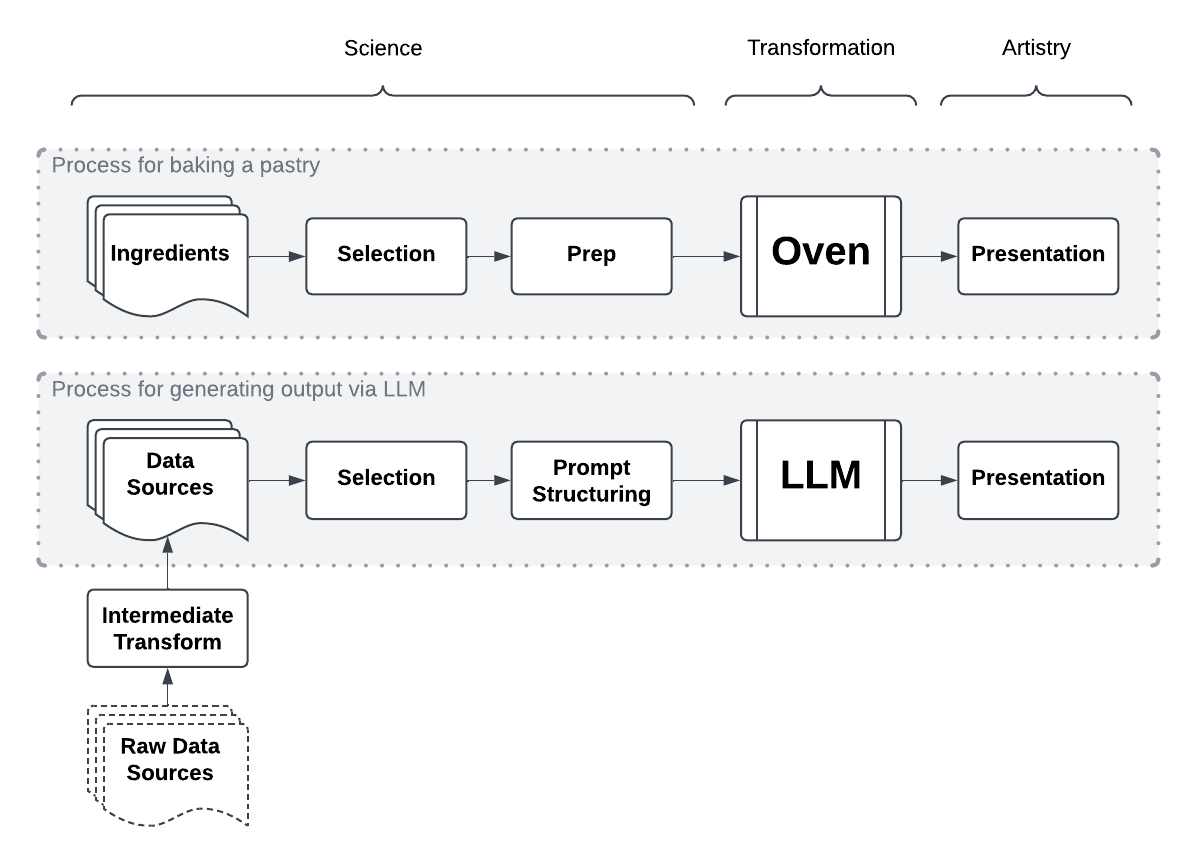 The processes are not dissimilar and it is clear that the LLM is a core part of this process, but perhaps the least important part of the process as far as achieving high quality and contextually relevant output is concerned.
The processes are not dissimilar and it is clear that the LLM is a core part of this process, but perhaps the least important part of the process as far as achieving high quality and contextually relevant output is concerned.
For most AI startups, the moat probably really comes down to how well the team can do ETL and how well the team understands the domain. Does the team have some insight into datasets in a particular domain? Have they come up with a novel or creative way to use that data? Do they understand how to shape and prepare that data given the constraints of LLMs? Can they combine the right pieces of data to achieve the desired output?
These two videos from Ownit AI’s work with retailer catalogs shows just how good the results can be when the underlying datasets have been extracted, transformed, loaded, and prepared for the LLM.
In Safeway’s case, the delta between the native Google-powered search results and the Ownit AI generated shelves is striking:
In Ulta’s case, the native platform misses entire classes of products when answering the query:
To achieve both, the process involved extracting and transforming the retailer’s catalog ahead of the selection of the correct context (indeed, it would be impossible to select the correct context without this initial transformation into a graph).
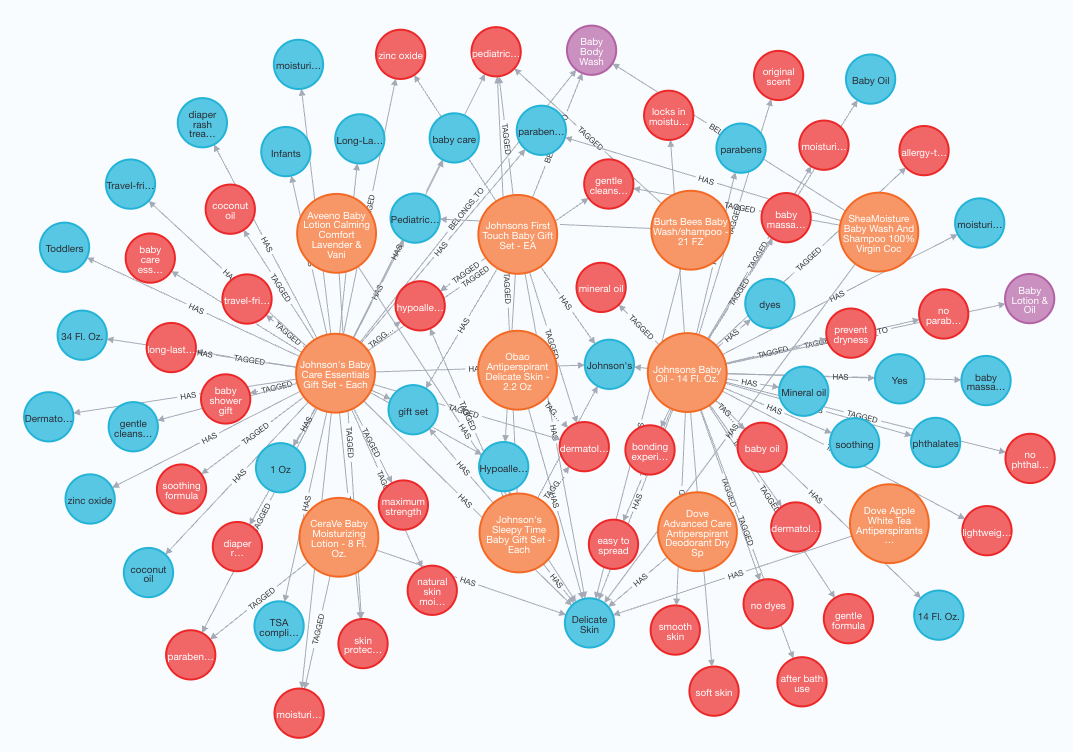 Much of the magic that enables Ownit to generate superior results is only possible from the acquisition and pre-processing of catalog data into a graph that has been augmented with AI-processed data ahead of time.
Much of the magic that enables Ownit to generate superior results is only possible from the acquisition and pre-processing of catalog data into a graph that has been augmented with AI-processed data ahead of time.
Closing Thoughts
What’s clear is that AI startups like Codebuff are anything but just another “wrapper for a 3rd party model”. That third party model is simply an oven; everyone has an oven, but few could claim to be world-class patissiers because at the end of the day, the oven is but an appliance that transforms the input ingredients to the output product. If the input is low effort with cheap ingredients, the chances of the output being high quality and world class — at least with the current magical ovens — are quite slim.
In the case of Codebuff, the art and science is how the team prepares, resolves, and structures the correct and relevant pieces of the codebase to feed into the LLM; it is not just a simple matter of shoving all of the codebase into the context. For Ownit, it is an analogous challenge (though perhaps a bit more abstract than a codebase) where we’ve invested an incredible amount of effort into acquiring, transforming, and mapping out product catalog data from retailers — classic ETL — so that we can accurately resolve the correct products.
For both companies — and other AI startups that seek to have a moat — a good portion of the effort and resultant software system is dedicated to designing and building the pipeline that performs the extract-transform-load and the smaller part of the effort is interfacing with the LLM. If you want to build an AI startup moat, everything starts with the ingredients (the data) and how adept you are in your preparation of the data before hitting “bake”.
Want to read more thoughts on AI? Check out I’m a Gen AI Maximalist and Why You Should Be, Too.
