Need for Speed: LLMs Beyond OpenAI with C#, .NET 8 SSE + Channels, Llama3, and Fireworks.ai
Summary
- While OpenAI’s GTP-4 is undoubtedly the champ when it comes to general purpose workloads, its overall throughput (or rather lack thereof) leaves a lot to be desired. This makes it great for “offline” workloads, but can leave it feeling less than suitable for applications where users are expecting more responsiveness and may even preclude some use cases due to the inferior UX.
- A recent post on Hackernews by the team at TheFastest.ai highlights just how big this disparity can be in terms of both the model and the platform. In particular, Groq.com (not to be confused with Musk’s Grok) and Fireworks.ai paired with Meta’s Llama 3 70B provides blazing throughput with minimal sacrifice in output compared to GPT-4 for some workloads.
- Combining this with C#/.NET 8
System.Threading.Channelsand server-sent events (SSE), novel use cases can be built that simply would not work with OpenAI due to the low throughput and high latency.
Intro
While we await GPT-5, few would argue that in May, 2024, OpenAI’s GPT-4 is still the champ when it comes to overall performance as an LLM. Where it comes up short is its relatively low throughput and high latency which can make it sub-optimal if the UX requires a more interactive experience.
What may not be obvious is just how low throughput it is if the use case has a need for speed.
A recent Hackernews thread led me to TheFastest.ai and I was quite intrigued by both the high throughput of Meta’s Llama 3 as well as two platforms: Groq.com and Fireworks.ai.
(The former is unfortunate in that it is often confused with Musk’s Grok AI).
In this article, we’ll explore building an app with Fireworks.ai, Meta Llama 3 8B/70B, .NET 8, System.Threading.Channels, and Server Sent Events (SSE).
💡 Full repo is available here: https://github.com/CharlieDigital/dn8-sk-llama3-fireworks. Follow the instructions in the
README.mdto get it up and running. Start by signing up for a free account and credits at Fireworks.ai
Measuring the Difference
The top of the stack is dominated by Llama-3 and Groq with Fireworks.ai rounding out the top 5 (we’ll discuss in a bit why teams should probably choose Fireworks)
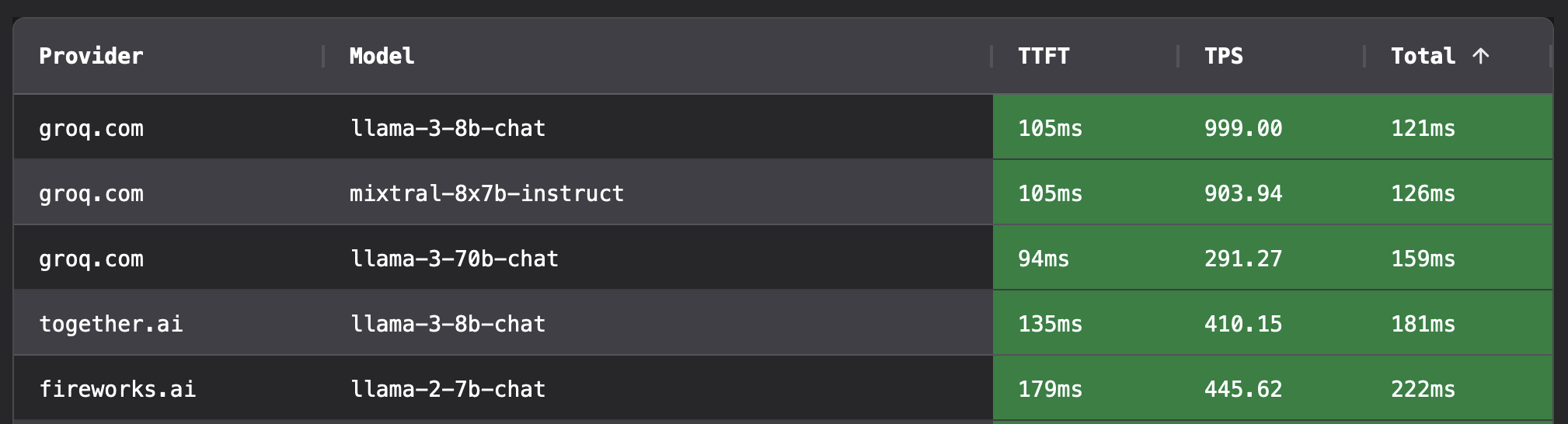 TTFT = Time to First Token, TPS = Tokens Per Second, Total = Total Time to Last Token
TTFT = Time to First Token, TPS = Tokens Per Second, Total = Total Time to Last Token
In contrast, OpenAI’s GPT-4 sits near the bottom:
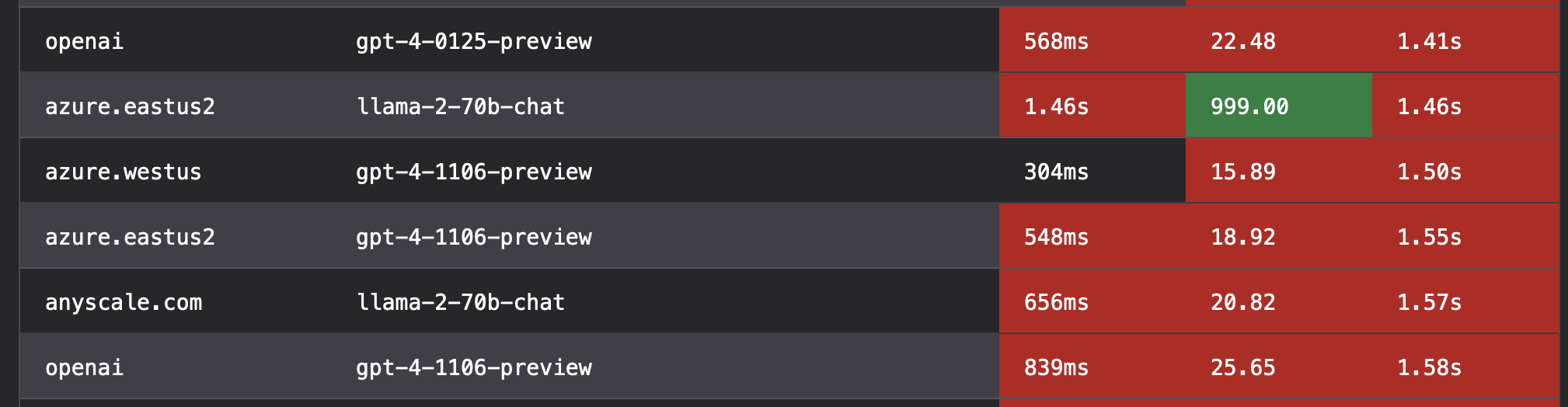 OpenAI GPT-4 nearly 10x slower to the last token
OpenAI GPT-4 nearly 10x slower to the last token
Note that these benchmarks are subject to change on any given day based on various factors; these screenshots should only be considered relevant at the time they were captured.
Anyone that has worked with OpenAI’s GPT-4 is already aware of just how poor the throughput is. But seeing it measured out like this just highlights how big this gap is. Groq’s Llama-3 70B is nearly 10x higher throughput to final token than GPT-4!
Given this, I have found that GPT-4 is really good for cases where: there is no need for interactivity (pre-processed), the workload requires the large context window, or where there is a need for “benchmark quality” output with complex prompts and contexts.
But what if the use case has a different need? What if there is a need for speed?
Kicking the Tires with Groq and Fireworks
One of the problems with OpenAI’s poor throughput is that it can subjectively make the user experience worse, even if the content ultimately adds value.
Using OpenAI’s ChatGPT, it may not be obvious as the SSE masks the fact that a chat response could take several seconds to complete. This lack of throughput with GPT-4 is not readily apparent until trying the alternatives.
Groq.com
Groq is an interesting platform as their claim to fame is custom hardware specifically designed for LLMs dubbed an “LPU” or “Language Processing Unit”:
The LPU is designed to overcome the two LLM bottlenecks: compute density and memory bandwidth. An LPU has greater compute capacity than a GPU and CPU in regards to LLMs. This reduces the amount of time per word calculated, allowing sequences of text to be generated much faster. Additionally, eliminating external memory bottlenecks enables the LPU Inference Engine to deliver orders of magnitude better performance on LLMs compared to GPUs.
At least on paper, it does seem to be more than just marketing hype and the platform is objectively high throughput.
But the main problem comes down to their current SaaS offering:
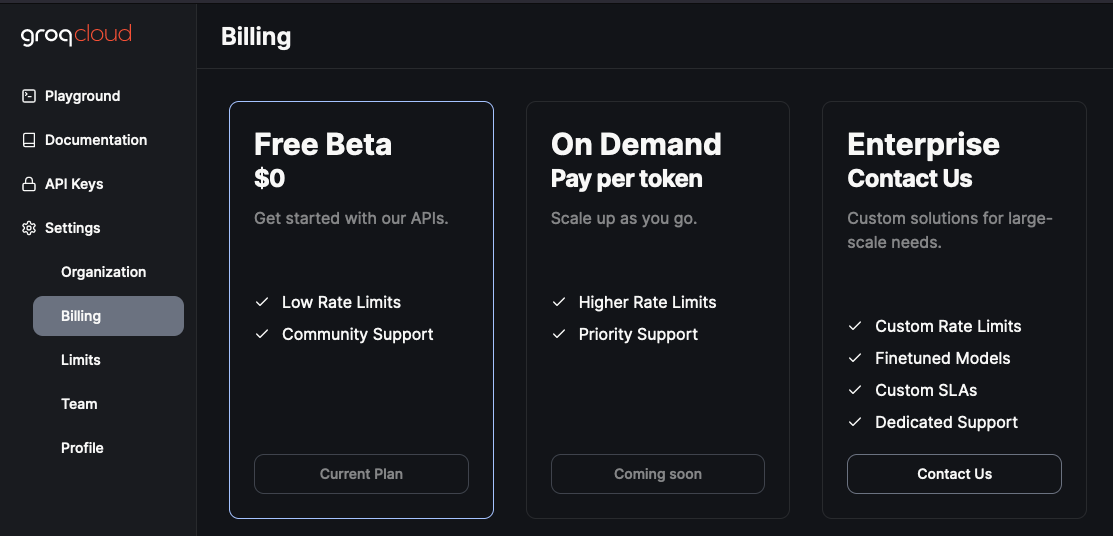 Groq currently lacks an intermediate paid tier with only free or enterprise billing.
Groq currently lacks an intermediate paid tier with only free or enterprise billing.
The free tier is only usable for experiments and even then, just barely:
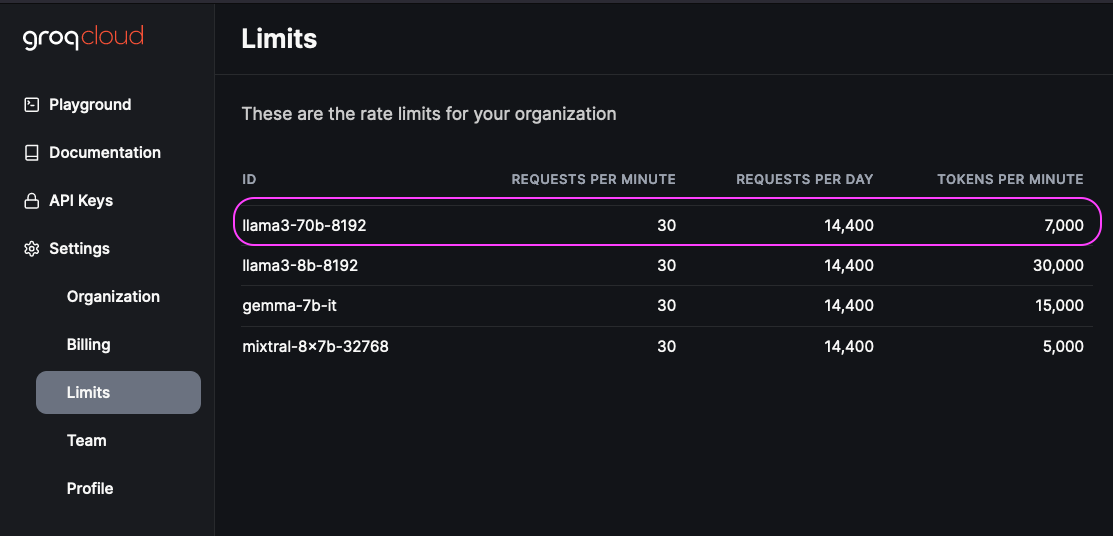 7000 tokens per minute is really easy to consume and it’s using a bucket-type token refresh algorithm; throttling happens easily during the development cycle.
7000 tokens per minute is really easy to consume and it’s using a bucket-type token refresh algorithm; throttling happens easily during the development cycle.
So even though Groq is quite fast, it’s unusable except for sandboxing and then possibly via their enterprise billing.
Fireworks.ai
As of this writing, Fireworks’ Llama-3 70B comes in at 9th overall and is the second fastest Llama-3 70B:
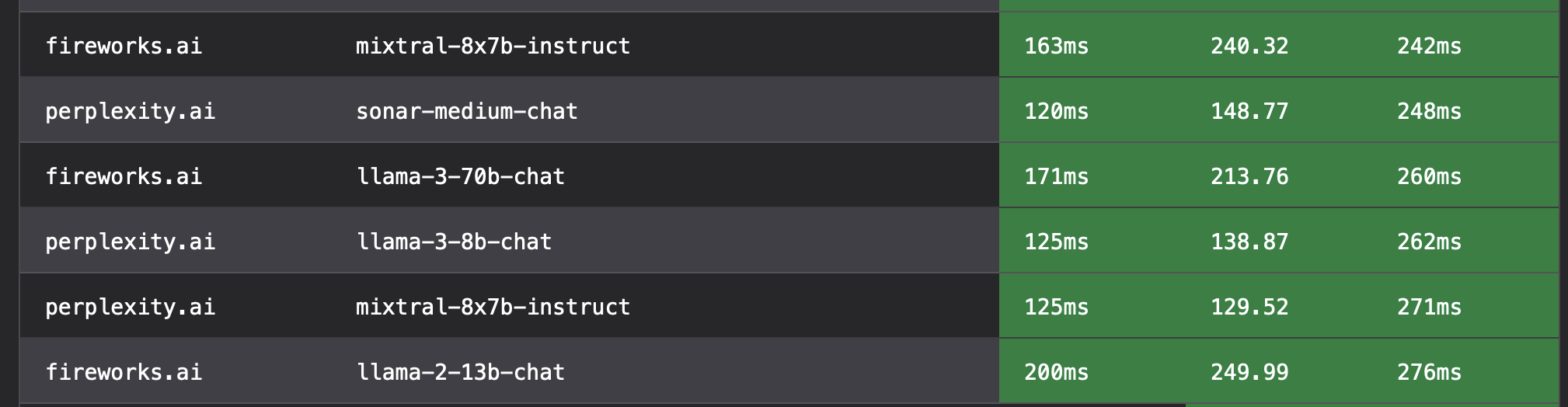 At 250ms to the last token, it only trails groq.com’s Llama 3 8B by 139ms
At 250ms to the last token, it only trails groq.com’s Llama 3 8B by 139ms
At 260ms to last token, it is still plenty fast while offering really good LLM performance comparable to something between GPT-3.5 and GPT-4 based on my use cases.
While Fireworks.ai also lacks an intermediate paid tier, the 600 RPM is usable for small apps and there is no hard token limit:
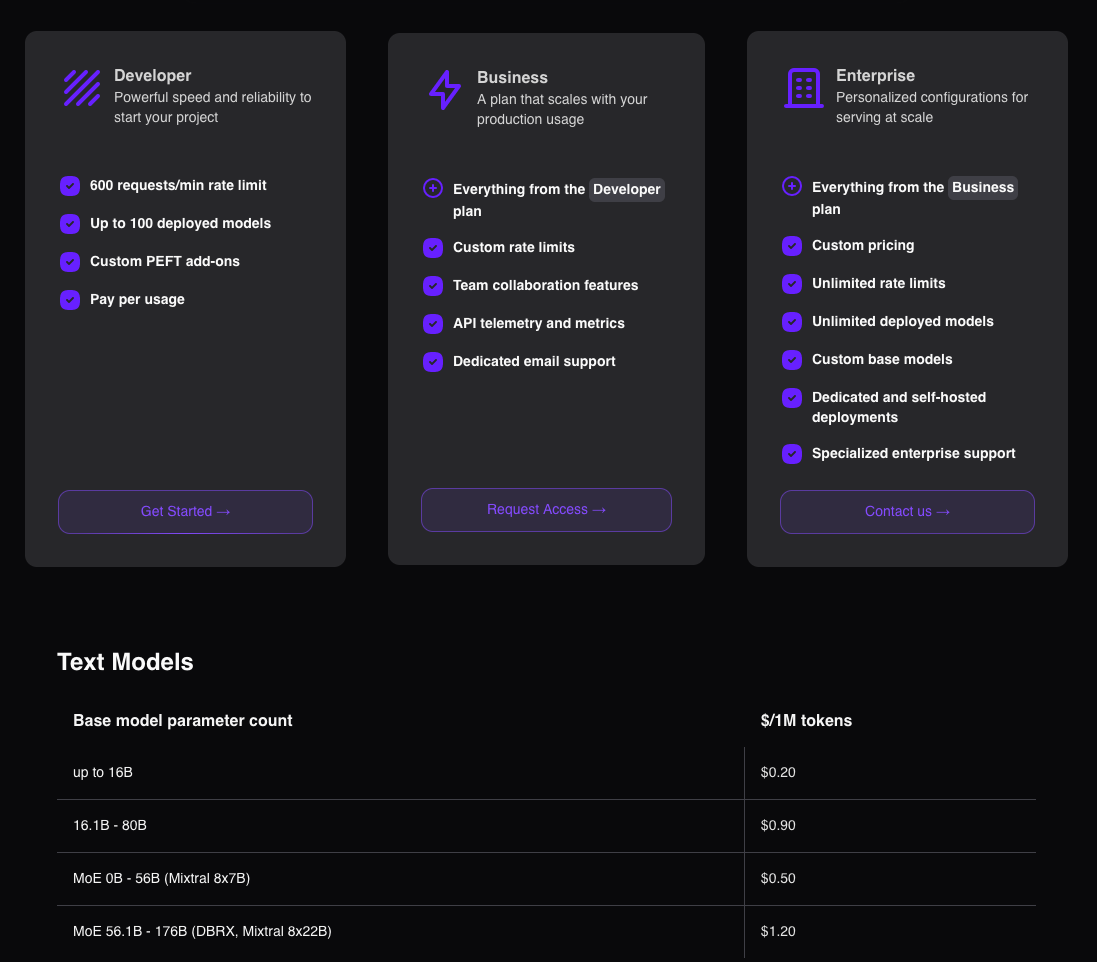 Sign up and you’ll get some free credits; enough for 1 million tokens generated
Sign up and you’ll get some free credits; enough for 1 million tokens generated
For teams trying to build something fast today, Fireworks.ai is probably the best bet. (No, I’m not getting paid by them)
A Practical Example with .NET 8, System.Threading.Channels, and Server Sent Events (SSE)
To take the greatest advantage of this incredible throughput, what is needed is a concurrent processing strategy that will allow generation through multiple streams at once and then coalescing into one final output stream to the front-end.
This is the perfect use case for combining .NET’s System.Threading.Channels along with Server Sent Events (SSE) to fully exploit this throughput and build a highly responsive generative AI experience.
I’ve previously written about both topics separately:
- .NET Task Parallel Library vs System.Threading.Channels
- Concurrent Processing in .NET 6 with System.Threading.Channels (Bonus: Interval Trees)
- Server Sent Events with .NET 7
Today, we’ll put them together and see what kind of interactive experience we can create with .NET 8 channels, Semantic Kernel, and gen AI!
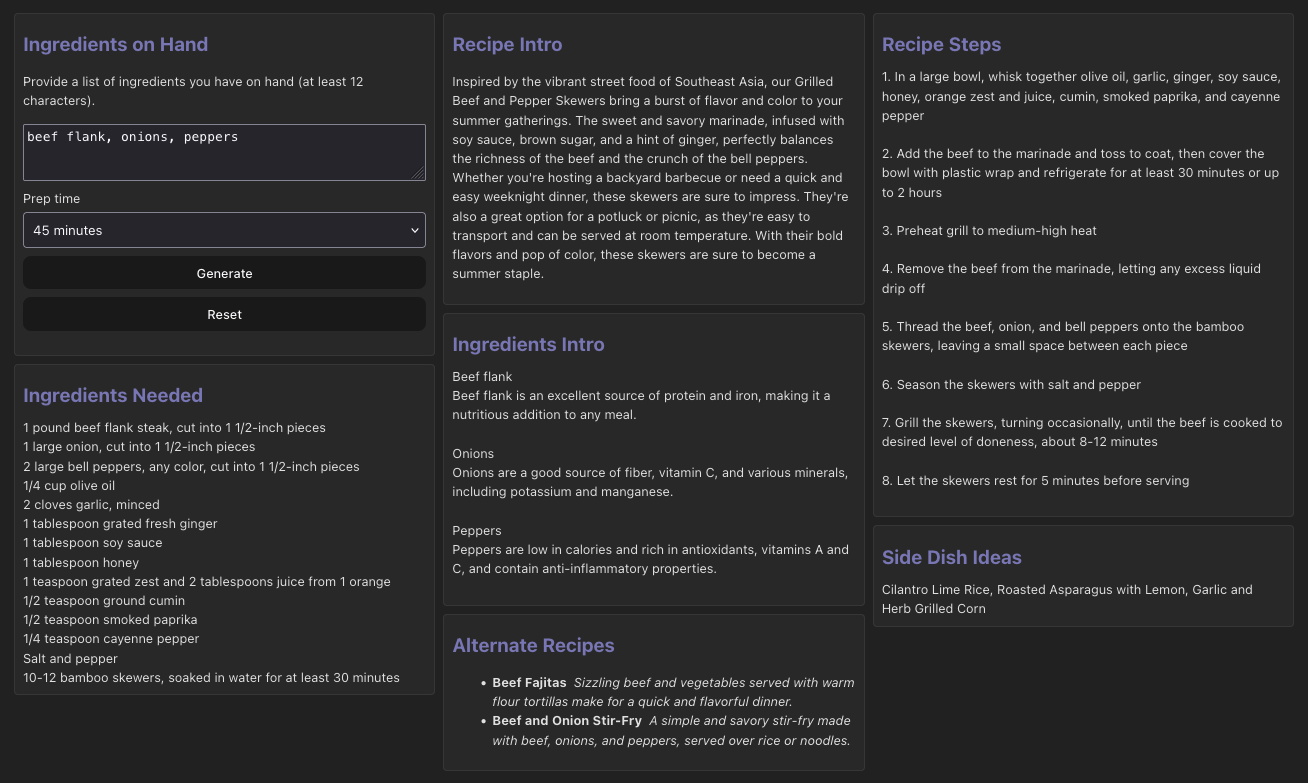
Our sample application will take a list of ingredients on hand plus a target prep time and then:
- Generate a list of recipes that can be made using the ingredients
- Pick one of the recipes at random
- Generate a list of all of the ingredients required for the recipe
- Generate an intro paragraph for the recipe
- Generate a short writeup about the nutritional information for each ingredient on hand
- Generate a short list of suggested side dishes
- Generate a list of steps
Steps 3-6 can run in parallel, but because we need to pick a recipe first, step 1-2 run first. Then we also need to wait for the full list of ingredients before starting to generate the steps.
Concurrent Execution with .NET Channels
The entrypoint of the API call is a single POST endpoint that will receive the request:
// 👇 The main entry point.
app.MapPost("/generate", async (
HttpContext context, // From dependency injection
RecipeGenerator generator, // From dependency injection
RecipeRequest request, // From the body
CancellationToken cancellation = default
) =>
{
context.Response.Headers.ContentType = "text/event-stream";
await generator.GenerateAsync(
request,
// Handler that writes the streaming response for each fragment
async (Fragment f) => {
await context.Response.WriteAsync(
$"data: {f.Part}|{f.Content}{Environment.NewLine}{Environment.NewLine}",
cancellation
);
await context.Response.Body.FlushAsync(cancellation);
}
);
});The RecipeGenerator.GenerateAsync method contains the main flow:
/// <summary>
/// The main entry point
/// </summary>
public async Task GenerateAsync(
RecipeRequest request,
Func<Fragment, Task> handler, // 👈 This is the hook to the HTTP response stream
CancellationToken cancellation = default
) {
var (ingredientsOnHand, prepTime) = request;
// 👇 (1) Generate the list of 3 recipes and pick one at random
var recipes = await GenerateRecipesAsync(ingredientsOnHand, prepTime, cancellation);
Console.WriteLine($"Generated {recipes.Length} recipes.");
var recipe = recipes[Random.Shared.Next(0, 2)];
// 👇 (2) Since we have all of the recipes, we aggregate as an HTML string
var alternates = recipes
.Where(r => r.Name != recipe.Name)
.Aggregate(new StringBuilder(), (html, r) => {
html.Append($"<li><b>{r.Name}</b> ");
html.Append($"<i>{r.Intro}</i></li>");
return html;
}).ToString();
// 👇 (3) This is our loop on the reader side of the channel; we start it first
var fragmentHandler = async () => {
while (await _channel.Reader.WaitToReadAsync()) {
if (_channel.Reader.TryRead(out var fragment)) {
await handler(fragment);
}
}
};
var completion = fragmentHandler();
// 👇 (4) Now we run the generation prompts concurrently
Task.WaitAll([
handler(new ("alt", alternates)),
GenerateIngredientsAsync(recipe, ingredientsOnHand, request.PrepTime, cancellation),
GenerateIntroAsync(recipe, cancellation),
GenerateIngredientIntroAsync(ingredientsOnHand, cancellation),
GenerateSidesAsync(recipe, cancellation)
]);
// 👇 (5) And wait for everything to complete.
_channel.Writer.Complete();
await completion;
}Each of the generation steps follows a similar pattern:
private async Task GenerateIntroAsync(
RecipeSummary recipe,
CancellationToken cancellation = default
) {
var prompt = "...";
await ExecutePromptAsync(
"int", // 👈 This matches the ID of a front-end target where the output goes
prompt,
new () {
MaxTokens = 250,
Temperature = 0.55,
TopP = 0
},
cancellation: cancellation
);
}And the method for executing the prompts:
/// <summary>
/// Executes the prompt and writes the result to the channel.
/// </summary>
private async Task ExecutePromptAsync(
string part,
string prompt,
OpenAIPromptExecutionSettings settings,
Action<string>? resultHandler = null,
string? modelOverride = null,
CancellationToken cancellation = default
) {
// 👇 Initialize our chat
var chat = _kernel.GetRequiredService<IChatCompletionService>(
modelOverride ?? "70b" // Use 70b if no override is specified.
);
var history = new ChatHistory();
var buffer = new StringBuilder();
history.AddUserMessage(prompt);
// 👇 Stream the response and write each part to our channel
await foreach (var message in chat.GetStreamingChatMessageContentsAsync(
history, settings, _kernel, cancellation
)
) {
await _channel.Writer.WriteAsync( // 👈 The writer end of our channel
new(part, message.Content ?? ""),
cancellation
);
buffer.Append(message.Content); // 👈 A buffer to hold the full output
}
var output = buffer.ToString();
// 👇 If the caller wants the full result, we have it here
resultHandler?.Invoke(output);
}The Kernel instance is configured during application startup via dependency injection:
// Program.cs
var builder = WebApplication.CreateBuilder(args);
var fireworksEndpoint = new Uri("https://api.fireworks.ai/inference/v1/chat/completions");
var groqEndpoint = new Uri("https://api.groq.com/openai/v1/chat/completions");
var config = builder.Configuration
.GetSection(nameof(RecipesConfig))
.Get<RecipesConfig>();
// Set up Semantic Kernel, registering as many LLMs as we need.
var kernelBuilder = Kernel.CreateBuilder();
var kernel = kernelBuilder
.AddOpenAIChatCompletion(
modelId: "accounts/fireworks/models/llama-v3-70b-instruct",
apiKey: config!.FireworksKey,
endpoint: fireworksEndpoint,
serviceId: "70b" // 👈 Use this serviceId by default for better results
)
.AddOpenAIChatCompletion(
modelId: "accounts/fireworks/models/llama-v3-8b-instruct",
apiKey: config!.FireworksKey,
endpoint: fireworksEndpoint,
serviceId: "8b" // 👈 Use this serviceId when we need more speed
)
.AddOpenAIChatCompletion(
modelId: "llama3-8b-8192",
apiKey: config!.GroqKey,
endpoint: groqEndpoint,
serviceId: "groq-8b" // 👈 Use this serviceId for max throughput
)
// Register other LLMs here.
.Build();
builder.Services
.Configure<RecipesConfig>(
builder.Configuration.GetSection(nameof(RecipesConfig))
)
.AddCors()
.AddSingleton(kernel) // 👈 Add our configured kernel as a singleton
.AddScoped<RecipeGenerator>();Simultaneous Streams with SSE
To help visualize this flow, check out the diagram below:
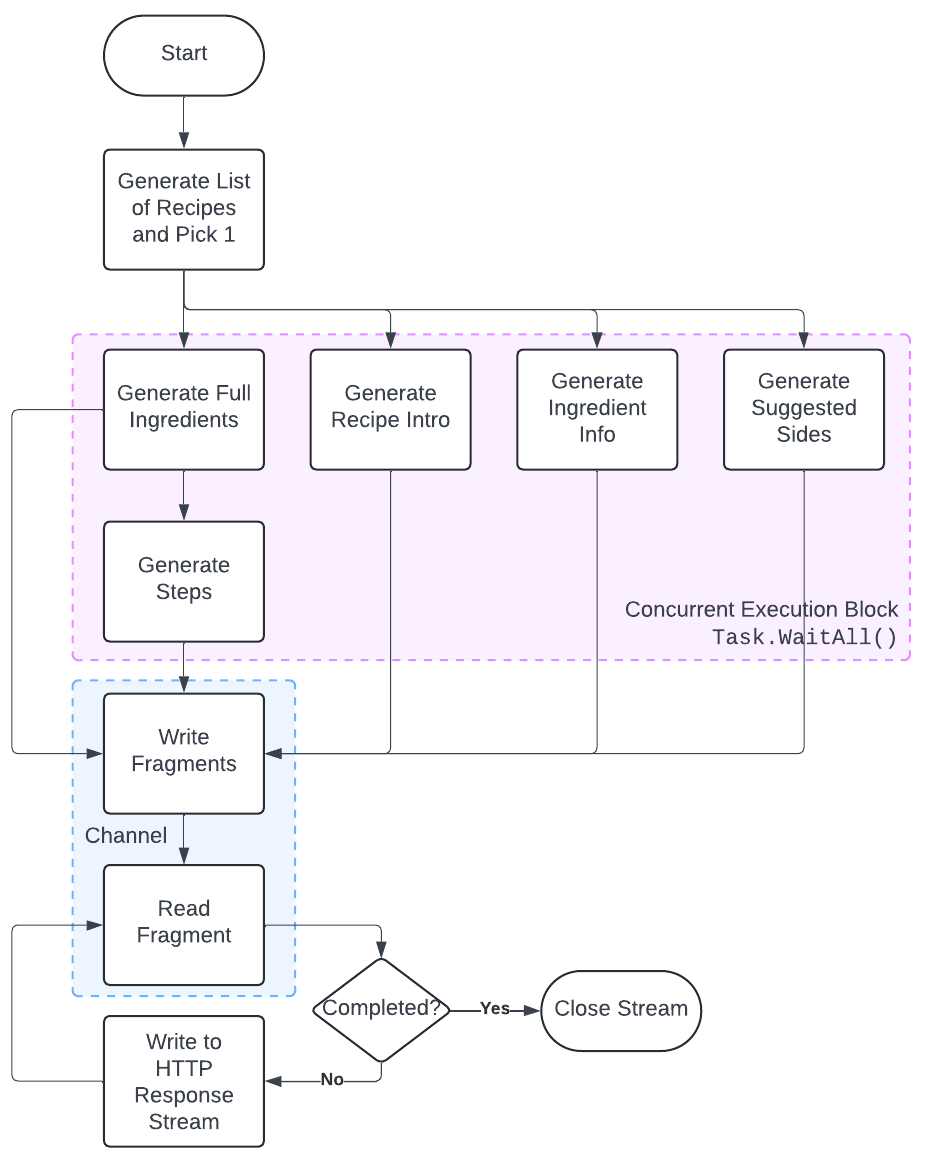
The Task.WaitAll block of code is handed the shared, thread-safe writer end of a Channel while the reader end is connected to the HTTP response stream via a callback.
That callback simply formats the Fragment per the required format spec for EventSource.
In this case:
data: ing|tomatoes
data: ing|basil
data: ste|3. Chop theThe front-end receives a stream of these messages which gets accumulated into different sections of the UI.
- The first part,
ingidentifies the front-end part that this content belongs to (“ingredients” in this case) - The text after the
|represents a set of output tokens written by the LLM
On the front-end, @microsoft/fetch-event-source is polyfilled for the native EventSource to allow the usage of POST.
Note: it is non-trivial to render the output as HTML either on the client side or on the server side. Part of the problem is that the output is generated partially so writing out
<results in the HTML entity<if we don’t have the rest of the element (assuming we output HTML from the backend). Probably the best solution is to “cache” the raw HTML text in a hidden element along with a rendered version.
The receiver takes each message and decodes it:
onmessage: (msg) => {
var payload = msg.data
var [part, content] = payload.split('|')
if (!part || !$el(`#${part}`)) {
return // Discard this message
}
// 👇 This is a hack to encode newlines and replace them here.
content = content.replace(/⮑/gi, "\n")
$el(`#${part}`).innerHTML += content
},A special note with text/event-stream is that double newlines indicate the end of a message block. So newlines need to be encoded somehow (there are many ways). In this case, using the single character ⮑ makes it easy to find and replace it with \n when we append the content.
The CSS simply needs to account for this:
#add, #ing, #ste {
white-space: pre-line;
}The HTML itself is simple:
<!-- This block holds the additional ingredients -->
<div class="additional">
<h2>Ingredients Needed</h2>
<!-- 👇 This ID matches the Fragment.Part -->
<div id="add"></div>
</div>
<!-- This block holds the steps -->
<div class="recipe">
<h2>Recipe Steps</h2>
<!-- 👇 This ID matches the Fragment.Part -->
<div id="ste"></div>
</div>Putting it Together
Now that all the parts are in place, running the app should yield the following experience:
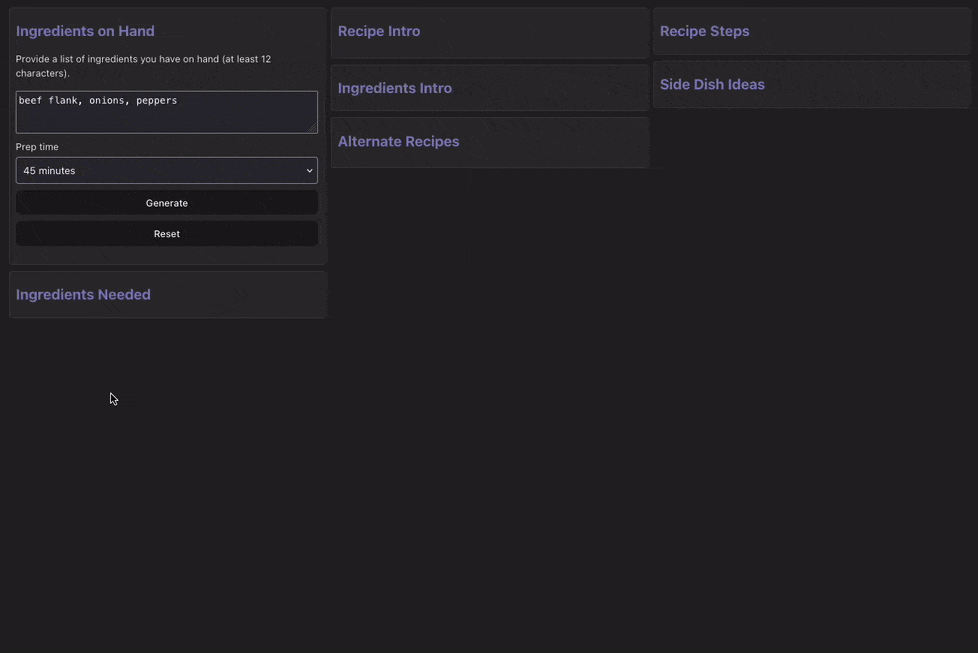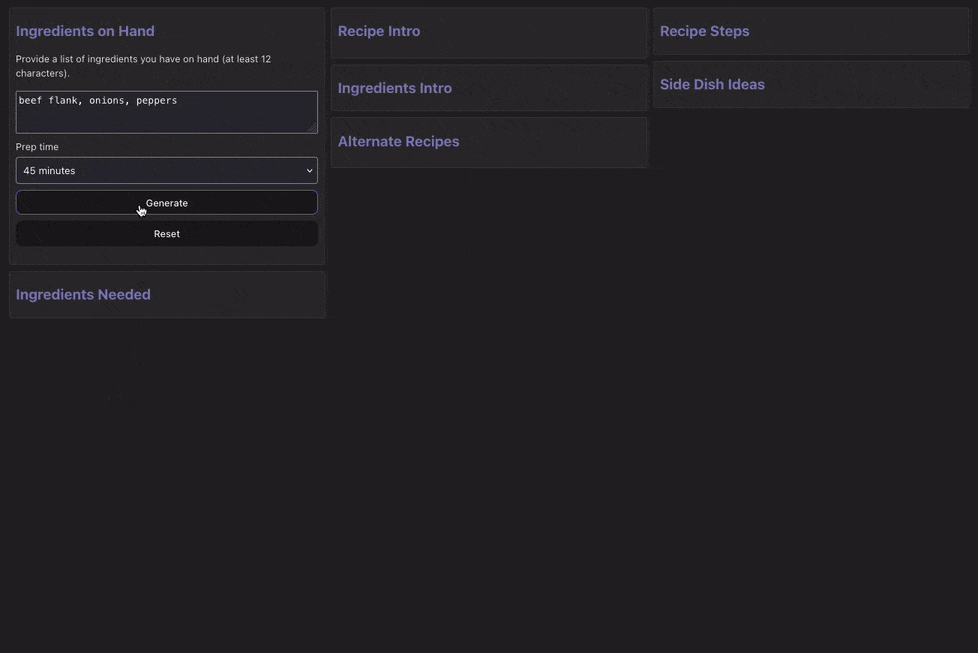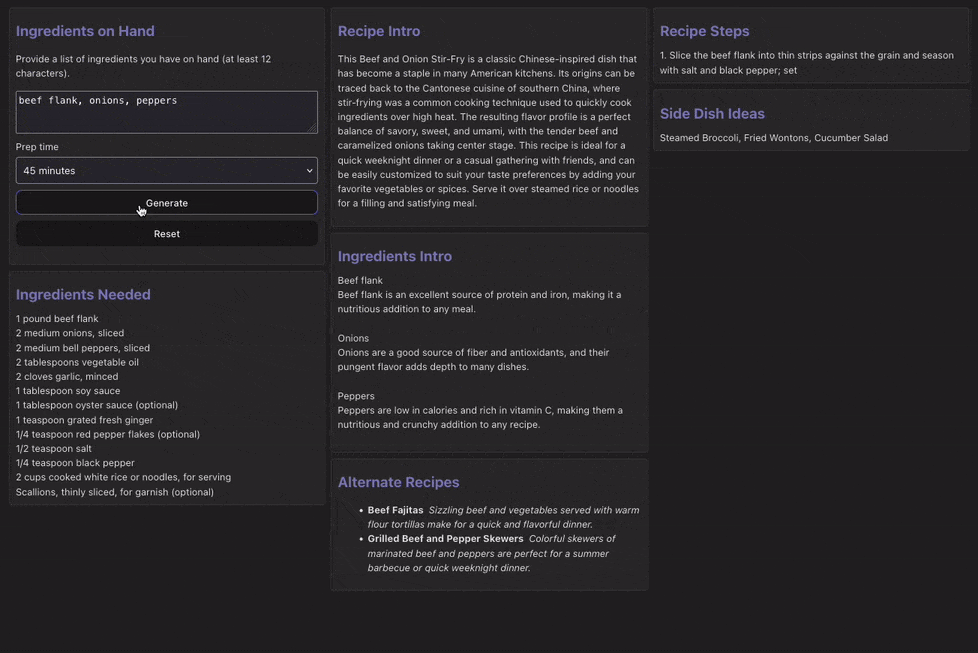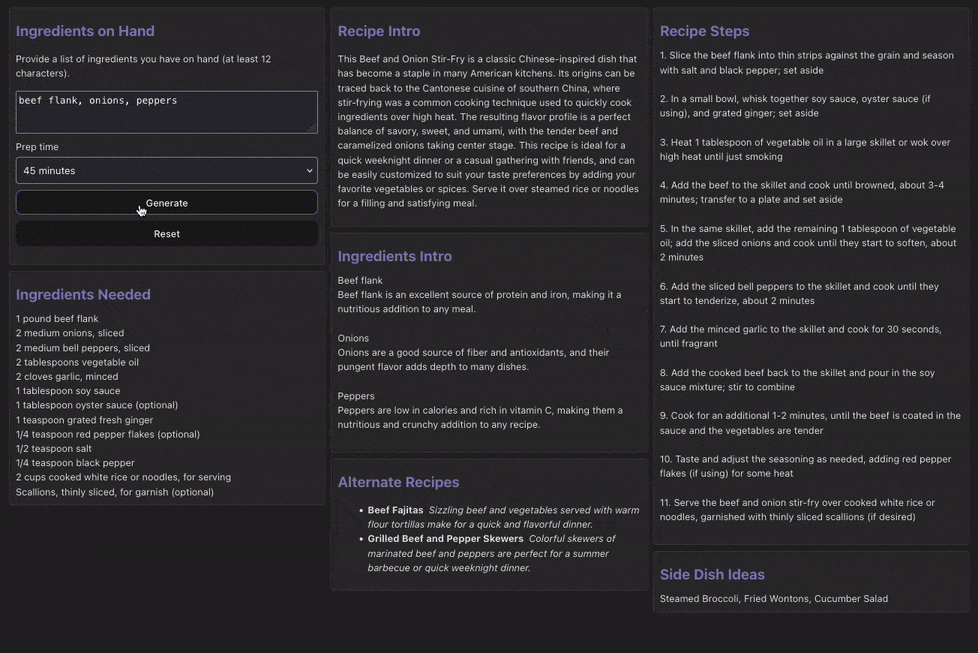
There is a slight initial delay as the call to generate the list of recipes is blocking.
However, once the list is generated and one is selected at random, the additional generation occurs concurrently with only the steps being blocked by the full list of ingredients (since we need that to generate accurate steps that reflect our full ingredient list).
Conclusion
For applications where the UX benefits from having higher throughput and you can make it work with smaller context windows, Fireworks.ai with Llama-3 8B/70B is absolutely a game changer; it lets teams build for use cases that would otherwise compromise the overall UX with the high latency of OpenAI’s GPT models.
Plugging that into a .NET 8 web API using System.Threading.Channels combined with SSE means that it is possible to concurrently generate multiple chunks of content and open up a new set of possibilities for leveraging generative AI whether the objective is to build more interactive gen AI experiences or simply speeding up your generative workflows.
The same techniques (minus SSE) can increase the throughput of your server generation workloads by processing multiple prompts in parallel using lower latency + higher throughput models and platforms.
💡 Full repo is available here: https://github.com/CharlieDigital/dn8-sk-llama3-fireworks
If you’d like to read more on .NET channels, check out:
